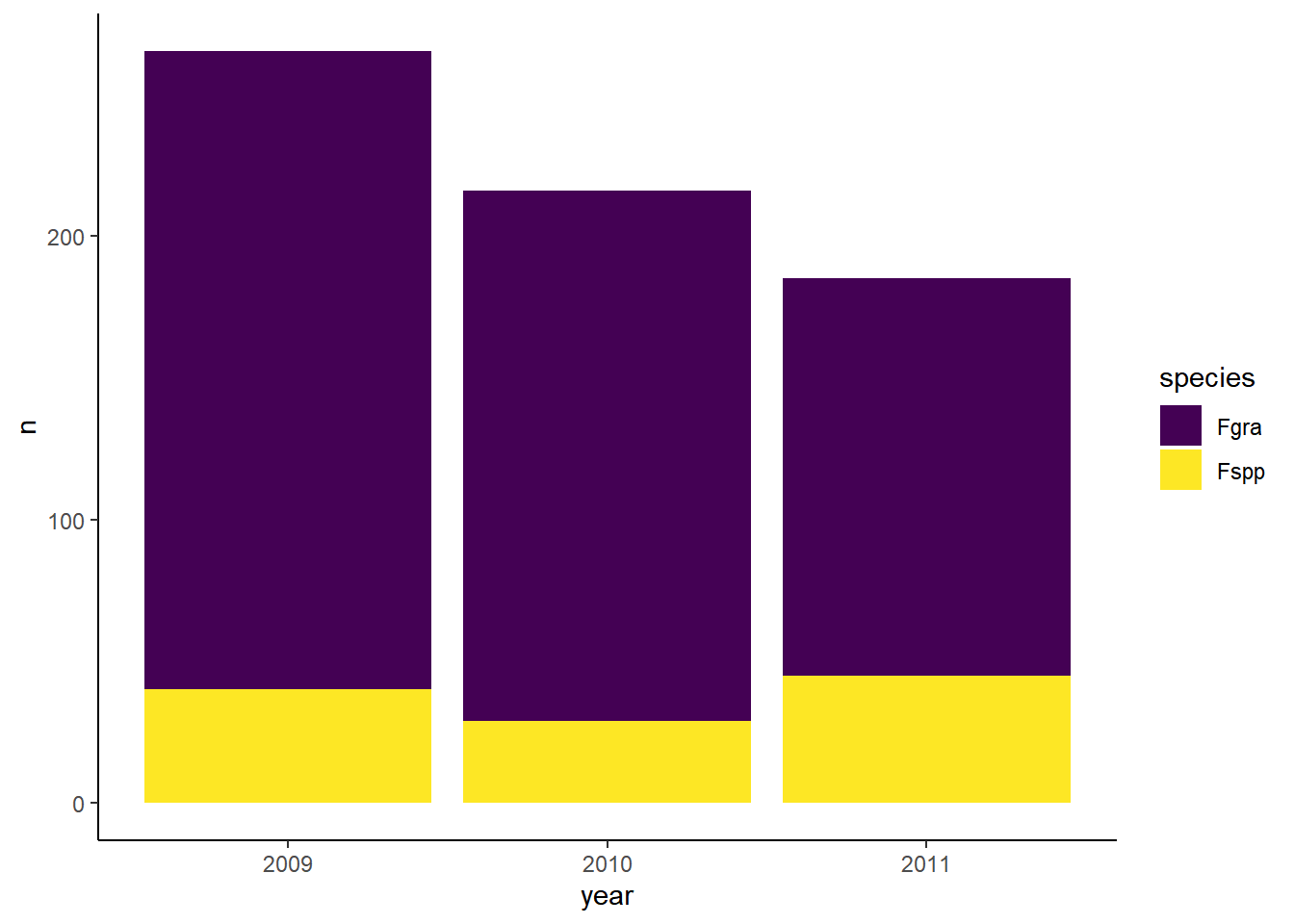Funções de visualização como head(), str(), glimpse()
2. Importação com Google Sheets
Importar dados diretamente da nuvem com gsheet
3. Manipulação de Dados
filter(), select(), group_by() e count()
Combinar dados com rbind()
4. Visualização com ggplot2
Gráficos de colunas (geom_col)
Boxplots (geom_boxplot)
Combinação de gráficos com patchwork
1. Leitura do Arquivo Excel
# Instalar e carregar o pacote readxl (se necessário)# install.packages("readxl")library(readxl)# Importar arquivo Excel (salve o arquivo na mesma pasta do projeto)dados <-read_excel("dados_exemplo.xlsx")# Visualizar os dadoshead(dados)
Com poucas linhas de código usando o dplyr, é possível:
Agrupar e contar dados;
Filtrar por estado ou ano;
Selecionar variáveis relevantes;
Combinar subconjuntos para comparar regiões.
Essas operações ajudam a limpar, organizar e entender melhor os dados antes de aplicar modelos ou criar visualizações. Uma análise bem feita começa com dados bem preparados e o dplyr facilita esse processo.
4. Visualização com ggplot2
library(ggplot2)survey_b |>group_by(year, species) |>count() |>ggplot(aes(year, n, fill = species)) +geom_col() +scale_fill_viridis_d() +theme_classic()
Visualizações com Estudos de Caso
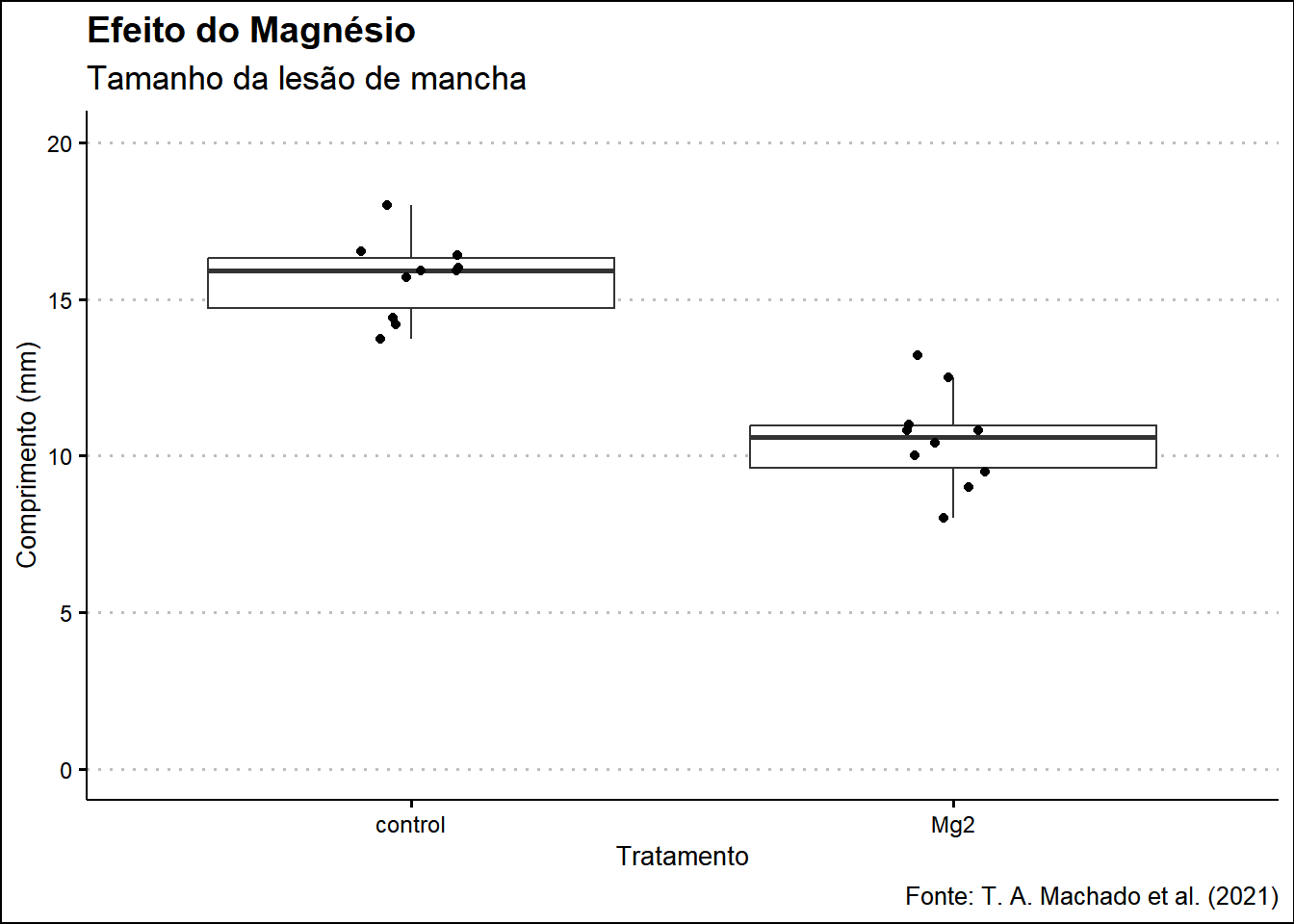
Exemplo 1: Efeito do Magnésio
plot_magnesio <- dados_mg |>ggplot(aes(trat, comp)) +geom_boxplot(fill ="white", outlier.colour =NA) +geom_jitter(width =0.1) +scale_y_continuous(limits =c(0, 20)) +labs(x ="Tratamento", y ="Comprimento (mm)",title ="Efeito do Magnésio",subtitle ="Tamanho da lesão de mancha",caption ="Fonte: T. A. Machado et al. (2021)" ) + ggthemes::theme_clean()plot_magnesio
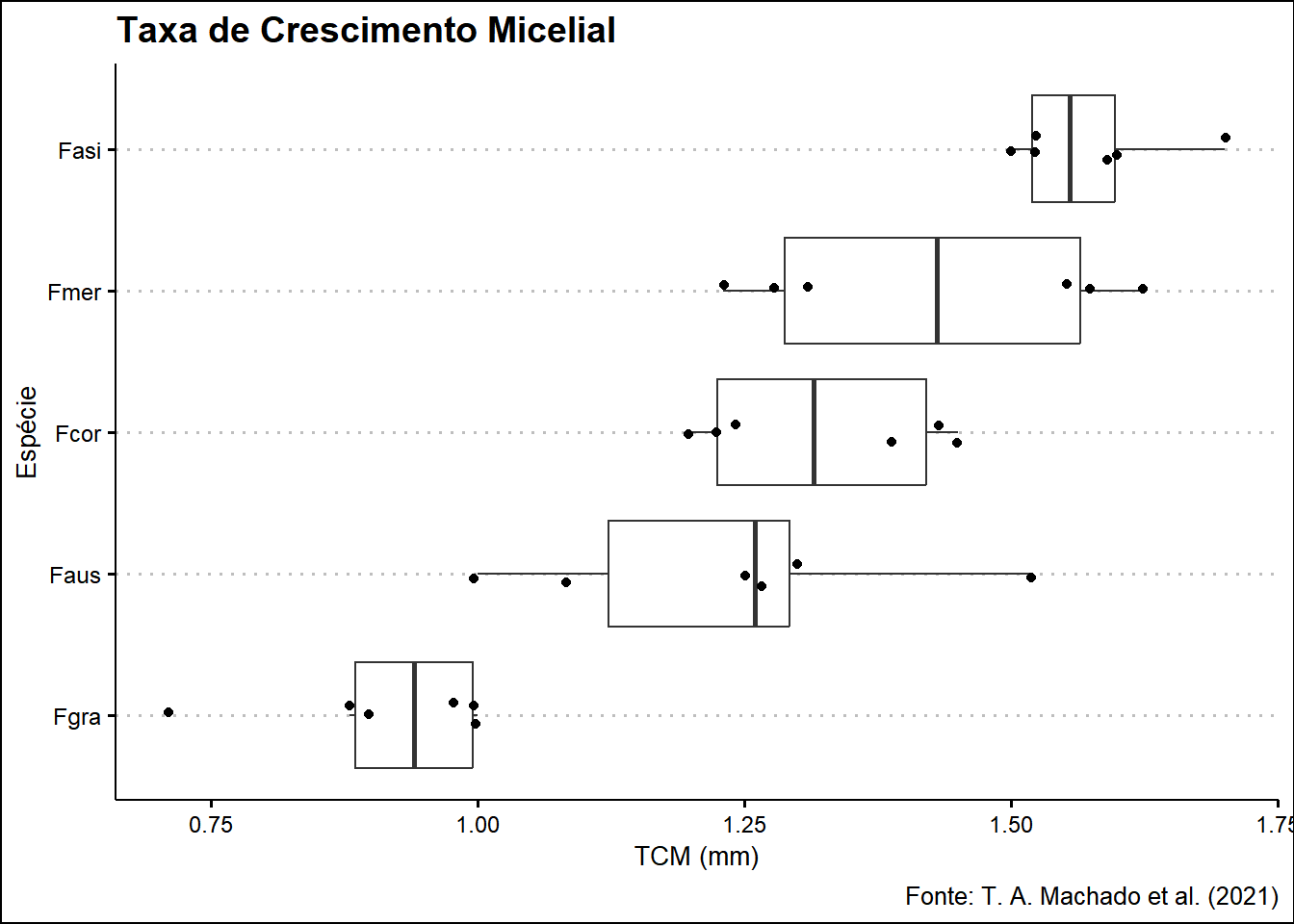
Exemplo 2: Crescimento Micelial
micelial <-gsheet2tbl("https://docs.google.com/spreadsheets/d/1bq2N19DcZdtax2fQW9OHSGMR0X2__Z9T/edit?gid=959387827#gid=959387827")plot_micelial <- micelial |>ggplot(aes(x =reorder(especie, tcm), y = tcm)) +geom_boxplot(fill ="white", outlier.colour =NA) +geom_jitter(width =0.1) +coord_flip() +labs(x ="Espécie", y ="TCM (mm)",title ="Taxa de Crescimento Micelial",caption ="Fonte: T. A. Machado et al. (2021)" ) + ggthemes::theme_clean()plot_micelial
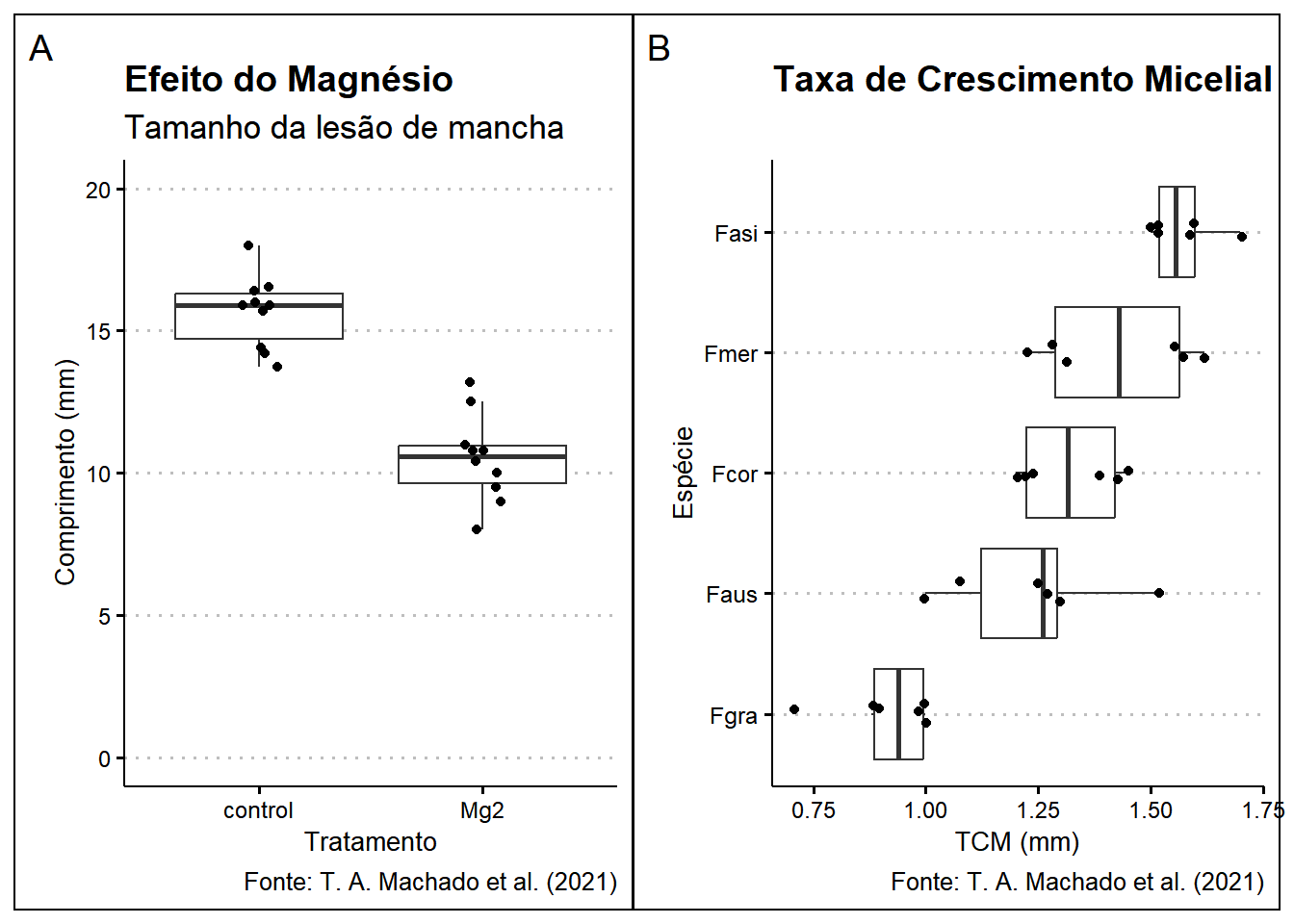
Combinação de Gráficos:
E por fim, vimos que dá pra exibir dois gráficos lado a lado diretamente no R sem depender de programas como PowerPoint ou ficar copiando imagem por imagem. Isso facilita a comparação entre visualizações e deixa o processo muito mais prático, tudo dentro do próprio ambiente de análise. Bem útil, né?